This spring, Valu8 data scientist Kajsa Norin supervised a stellar thesis project undertaken by two brilliant KTH students, Sam Taheri and Jacob Lundgren. Partnering with Valu8 Company Intelligence, they dived deep into various NLP methods for company classification – comparing traditional approaches such as stemming, lemmatisation and tfidf with models like SVM and logistic regression, to the more modern transformer models, using both pre-trained contextual embeddings and fine-tuning a BERT classifier.
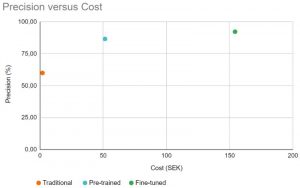
While they suspected that a fine-tuned model would perform the best, it’s interesting to see the precision versus cost graph and how it tapers off. Not included in the graph is the use of large foundation models such as GPT-4 – some preliminary tests would put the precision slightly higher but the cost would 1000-fold with the current API prices.
It shows that bigger is not always better and choosing a model is always about weighing the trade-offs, especially when cost is a factor.
Thanks again for a brilliant thesis, Sam and Jacob!
Link for anyone who’s interested: https://lnkd.in/dT_fe88K
